并发的三大特性
要理解产生这个问题的原因,我们就需要对并发三大特性有所了解。
并发三大特性指的是:可见性、有序性、原子性。
可见性
在单核时代,所有的线程都是在一颗 CPU 上执行,CPU 缓存与内存的数据一致性容易解决。因为所有线程都是操作同一个 CPU 的缓存,一个线程对缓存的写,对另外一个线程来说一定是可见的。例如在下面的图中,线程 A 和线程 B 都是操作同一个 CPU 里面的缓存,所以线程 A 更新了变量 V 的值,那么线程 B 之后再访问变量 V,得到的一定是 V 的最新值(线程 A 写过的值)。
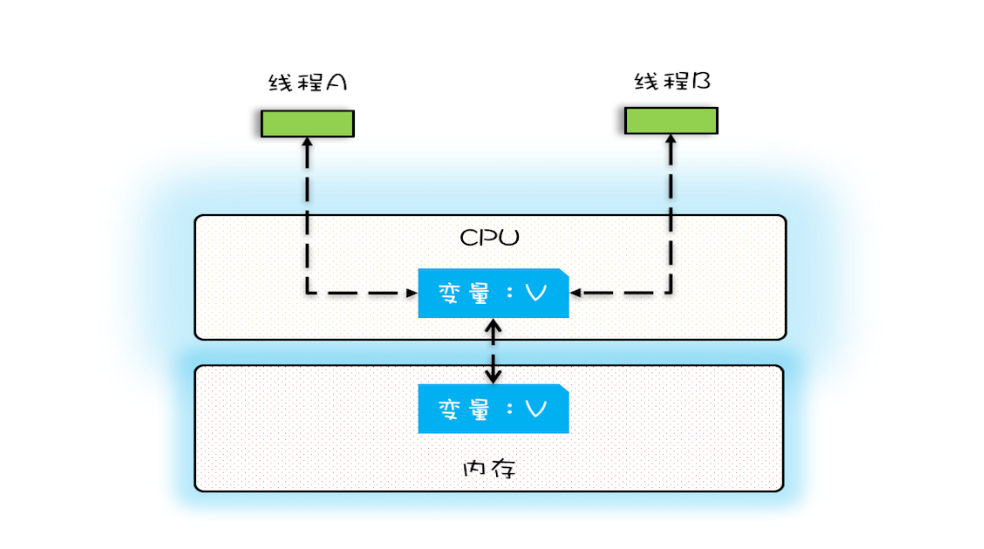
一个线程对共享变量的修改,另外一个线程能够立刻看到,我们称为可见性。
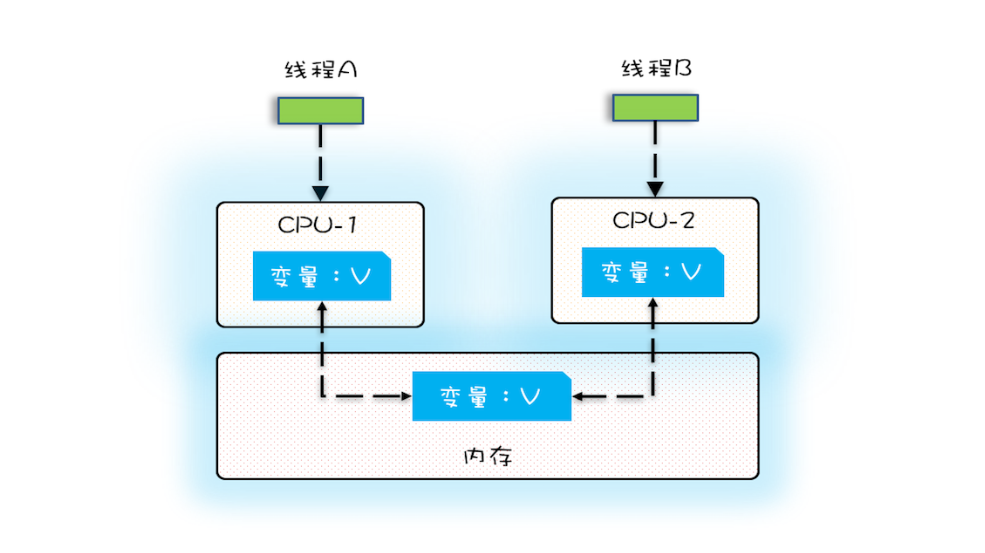
多核时代,每颗 CPU 都有自己的缓存,这时 CPU 缓存与内存的数据一致性就没那么容易解决了,当多个线程在不同的 CPU 上执行时,这些线程操作的是不同的 CPU 缓存。比如下图中,线程 A 操作的是 CPU-1 上的缓存,而线程 B 操作的是 CPU-2 上的缓存,很明显,这个时候线程 A 对变量 V 的操作对于线程 B 而言就不具备可见性了。这个就属于硬件程序员给软件程序员挖的“坑”。
可见性的例子:
public class VisibilityTest {
private boolean flag = true;
private int count = 0;
public void refresh() {
flag = false;
System.out.println(Thread.currentThread().getName() + "修改flag为false");
}
public void load() {
System.out.println(Thread.currentThread().getName() + "开始执行....");
while (flag) {
count++;
}
System.out.println(Thread.currentThread().getName() + "跳出循环:count=" + count);
}
public static void main(String[] args) throws InterruptedException {
VisibilityTest test = new VisibilityTest();
Thread threadA = new Thread(() -> test.load(), "threadA");
threadA.start();
Thread.sleep(1000);
Thread threadB = new Thread(() -> test.refresh(), "threadB");
threadB.start();
}
}原子性
由于 IO 太慢,早期的操作系统就发明了多进程,即便在单核的 CPU 上我们也可以一边听着歌,一边写 Bug,这个就是多进程的功劳。
操作系统允许某个进程执行一小段时间,例如 50 毫秒,过了 50 毫秒操作系统就会重新选择一个进程来执行(我们称为“任务切换”),这个 50 毫秒称为“时间片”。
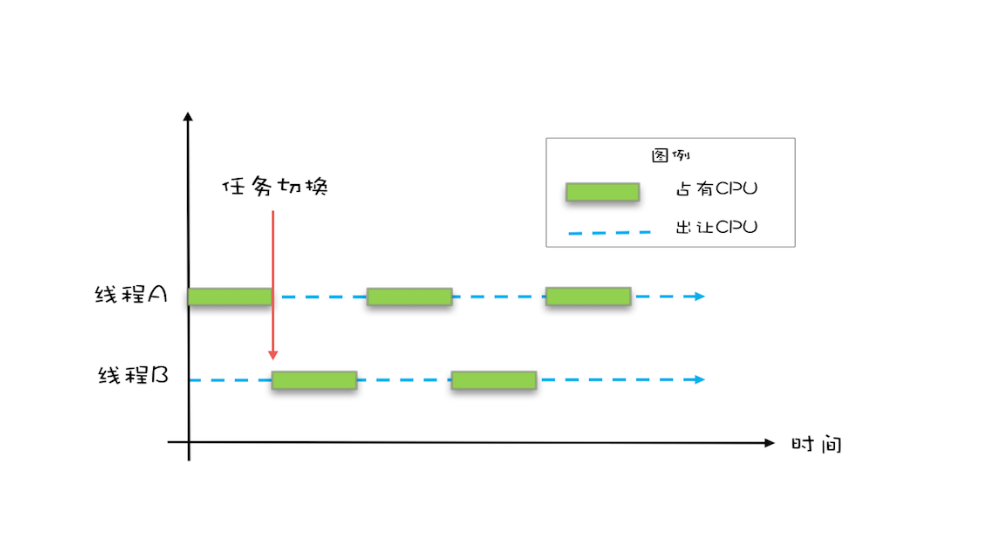
在一个时间片内,如果一个进程进行一个 IO 操作,例如读个文件,这个时候该进程可以把自己标记为“休眠状态”并出让 CPU 的使用权,待文件读进内存,操作系统会把这个休眠的进程唤醒,唤醒后的进程就有机会重新获得 CPU 的使用权了。
这里的进程在等待 IO 时之所以会释放 CPU 使用权,是为了让 CPU 在这段等待时间里可以做别的事情,这样一来 CPU 的使用率就上来了;此外,如果这时有另外一个进程也读文件,读文件的操作就会排队,磁盘驱动在完成一个进程的读操作后,发现有排队的任务,就会立即启动下一个读操作,这样 IO 的使用率也上来了。
Java 并发程序都是基于多线程的,自然也会涉及到任务切换,任务切换的时机大多数是在时间片结束的时候,我们现在基本都使用高级语言编程,高级语言里一条语句往往需要多条 CPU 指令完成,例如上面代码中的count += 1,至少需要三条 CPU 指令。
指令 1:首先,需要把变量 count 从内存加载到 CPU 的寄存器;
指令 2:之后,在寄存器中执行 +1 操作;
指令 3:最后,将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
操作系统做任务切换,可以发生在任何一条 CPU 指令执行完,是的,是 CPU 指令,而不是高级语言里的一条语句。对于上面的三条指令来说,我们假设 count=0,如果线程 A 在指令 1 执行完后做线程切换,线程 A 和线程 B 按照下图的序列执行,那么我们会发现两个线程都执行了 count+=1 的操作,但是得到的结果不是我们期望的 2,而是 1。
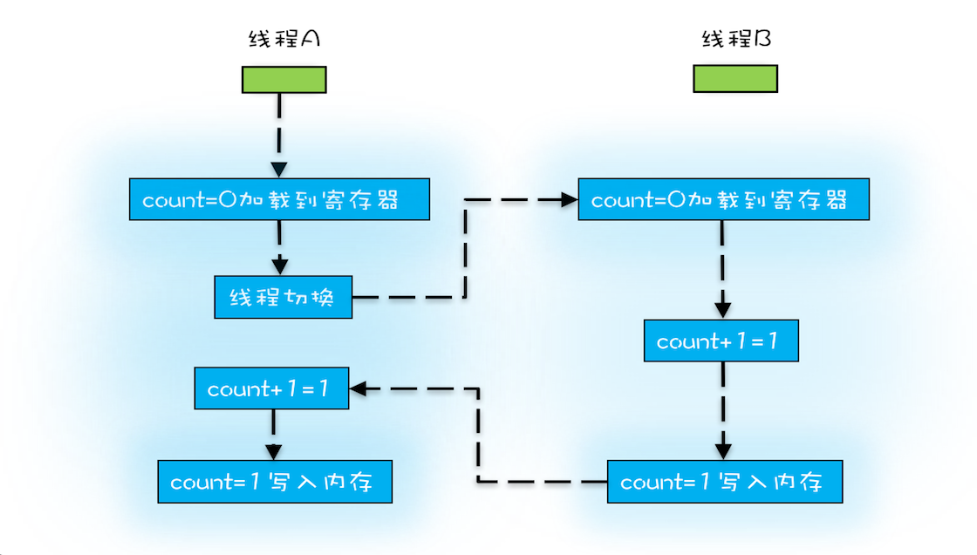
我们潜意识里面觉得 count+=1 这个操作是一个不可分割的整体,就像一个原子一样,线程的切换可以发生在 count+=1 之前,也可以发生在 count+=1 之后,但就是不会发生在中间。我们把一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性。CPU 能保证的原子操作是 CPU 指令级别的,而不是高级语言的操作符,这是违背我们直觉的地方。因此,很多时候我们需要在高级语言层面保证操作的原子性。
有序性
有序性指的是程序按照代码的先后顺序执行。编译器为了优化性能,有时候会改变程序中语句的先后顺序,例如程序中:“a=6;b=7;”编译器优化后可能变成“b=7;a=6;”,在这个例子中,编译器调整了语句的顺序,但是不影响程序的最终结果。不过有时候编译器及解释器的优化可能导致意想不到的 Bug。
public class ReOrderTest {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
int i = 0;
while (true) {
i++;
x = 0;
y = 0;
a = 0;
b = 0;
Thread threadA = new Thread(() -> {
shortWait(20000);
a = 1;
UnsafeFactory.getUnsafe().storeFence(); // 内存屏障
x = b;
});
Thread threadB = new Thread(() -> {
b = 1;
y = a;
});
threadA.start();
threadB.start();
threadA.join();
threadB.join();
System.out.println("第" + i + "次(" + x + "," + y + ")");
if (x == 0 && y == 0) {
break;
}
}
}
public static void shortWait(long interval) {
long start = System.nanoTime();
long end;
do {
end = System.nanoTime();
} while (start + interval >= end);
}
}为什么会出现指令重排序?
计算机在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排。
为什么指令重排序可以提高性能?
简单地说,每一个指令都会包含多个步骤,每个步骤可能使用不同的硬件。因此,流水线技术产生了,它的原理是指令1还没有执行完,就可以开始执行指令2,而不用等到指令1执行结束之后再执行指令2,这样就大大提高了效率。
但是,流水线技术最害怕中断,恢复中断的代价是比较大的,所以我们要想尽办法不让流水线中断。指令重排就是减少中断的一种技术。
a = b + c;
d = e - f ;先加载b、c(注意,即有可能先加载b,也有可能先加载c),但是在执行add(b,c)的时候,需要等待b、c装载结束才能继续执行,也就是增加了停顿,那么后面的指令也会依次有停顿,这降低了计算机的执行效率。
为了减少这个停顿,我们可以先加载e和f,然后再去加载add(b,c),这样做对程序(串行)是没有影响的,但却减少了停顿。既然add(b,c)需要停顿,那还不如去做一些有意义的事情。
综上所述,指令重排对于提高CPU处理性能十分必要。虽然由此带来了乱序的问题,但是这点牺牲是值得的。
指令重排一般分为以下三种:
编译器优化重排
编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
指令并行重排
现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性(即后一个执行的语句无需依赖前面执行的语句的结果),处理器可以改变语句对应的机器指令的执行顺序。
内存系统重排
由于处理器使用缓存和读写缓存冲区,这使得加载(load)和存储(store)操作看上去可能是在乱序执行,因为三级缓存的存在,导致内存与缓存的数据同步存在时间差。
指令重排可以保证串行语义一致,但是没有义务保证多线程间的语义也一致。所以在多线程下,指令重排序可能会导致一些问题。